雪重
Python Developer
知识 汗水 灵感 机遇
如何构造mmc4形式的多模态数据集
mmc4数据集【https://github.com/allenai/mmc4】是一个扩展了仅文本C4语料库的数据集,其中交错了图像和文本。该数据集涵盖了日常主题,如烹饪、旅行、科技等,在过滤掉NSFW图像、广告等后,该语料库包含103M个文档,其中交错了585M个图像和43B个英语标记。
数据格式如下
{'image_info': [{'face_detections': None,
'image_name': 'b9040a0dbb22.jpg',
'matched_sim': 0.27694183588027954,
'matched_text_index': 2,
'raw_url': 'http://www.hfitinfo.com/honda_fit_pics/3/2/index.90.jpg'},
{'face_detections': None,
'image_name': 'db1c21bc8474.jpg',
'matched_sim': 0.3234919607639313,
'matched_text_index': 1,
'raw_url': 'http://www.hfitinfo.com/honda_fit_pics/3/2/index.91.jpg'}],
'similarity_matrix': [[0.24363446235656738,
0.31758785247802734,
0.27694183588027954],
[0.2233106791973114,
0.3234919607639313,
0.26118797063827515]],
'text_list': ['When you lock the door using the lock tab on the driver’s '
'door, all of the other doors and tailgate lock at the same '
'time.',
'Press the master door lock switch in as shown to lock or '
'unlock all doors and the tailgate.',
'When you lock/unlock the driver’s door and tailgate using the '
'master lock switch, all the other doors lock/ unlock at the '
'same time.'],
'url': 'http://www.hfitinfo.com/hofi-48.html',
'could_have_url_duplicate': 0 }
text_list:文本句子列表
similarity_matrix:文本图片相似度矩阵
image_info:图片列表
matched_text_index:表示该图像所匹配的句子的索引
matched_sim:匹配索引处图像与句子之间的相似度
如何构造一份中文mmc4形式的多模态数据集呢?核心就是计算文本图片相似度矩阵,找到最优匹配。
引入如下工具:
Chinese-CLIP:https://github.com/OFA-Sys/Chinese-CLIP/tree/master
CLIP模型的中文版本,使用大规模中文数据进行训练(~2亿图文对),旨在帮助用户快速实现中文领域的图文特征&相似度计算、跨模态检索、零样本图片分类等任务
Munkres' Assignment Algorithm,也被称为匈牙利算法(Hungarian Algorithm)
是一种用于解决赋值问题的有效算法。赋值问题是最优化问题的一种,其中的目标是在成本矩阵中找到总成本最小的赋值方案,这个算法保证了在有限的步骤内找到总成本最小的赋值方案。
代码实现:
1.jpg

2.jpg

3.jpg

# -*- coding:utf-8 -*-
# @Author: zp
# @Time: 2023/9/26 17:11
import torch
import cn_clip.clip as clip
import numpy as np
from cn_clip.clip import load_from_name, available_models, model
from PIL import Image
from scipy.optimize import linear_sum_assignment
np.set_printoptions(suppress=True, formatter={'float_kind': '{:0.6f}'.format})
print("Available models:", available_models())
# 加载模型和处理器
device = "cuda" if torch.cuda.is_available() else "cpu"
print("use device", device)
model, preprocess = load_from_name("ViT-L-14", device=device, download_root='./')
model.eval()
# 加载并处理多个图像
image_paths = ["1.jpg", "2.jpg", "3.jpg"]
images = torch.stack([preprocess(Image.open(path)) for path in image_paths]).to(device)
# 准备多段文本
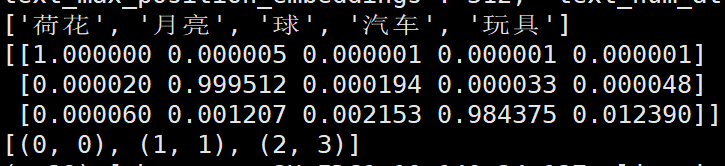
texts = ["荷花", "月亮", "球", "汽车", "玩具"]
print(texts)
texts = clip.tokenize(texts).to(device)
# 通过模型获取图像和文本的特征
with torch.no_grad():
logits_per_image, logits_per_text = model.get_similarity(images, texts)
similarity_matrix = logits_per_image.softmax(dim=-1).cpu().numpy()
print(similarity_matrix)
row_ind, col_ind = linear_sum_assignment(1 - similarity_matrix)
result = list(zip(row_ind, col_ind))
print(result)